

China’s AI Breakthrough and the Global Race for Artificial Intelligence Supremacy
On November 3, 2022, OpenAI launched ChatGPT, and in an instant, the world changed. What had once seemed like a distant, futuristic technology—artificial intelligence capable of human-like conversation — was suddenly available to everyone. ChatGPT became the fastest-growing consumer application in history, sparking widespread excitement, fear, and a global race to develop AI. Over the next year, major players such as OpenAI, Google DeepMind, Anthropic, and Meta competed fiercely to dominate the AI landscape. In recent weeks, DeepSeek, an emerging Chinese AI company, has gained significant attention by introducing a model that competes with some of the most advanced AI systems available today. While ChatGPT’s launch marked the beginning of the generative AI revolution, DeepSeek’s sudden rise is now challenging assumptions about who leads the industry and how AI can be built more efficiently.

What is DeepSeek?
DeepSeek is a Chinese AI company that emerged in 2023 with a strong commitment to developing Artificial General Intelligence (AGI). Unlike traditional AI models that rely on vast amounts of computing power, DeepSeek has taken a unique approach by using a Mixture-of-Experts (MoE) architecture. This allows the model to selectively activate certain subsets of its neural network rather than engaging all parameters at once, leading to greater efficiency. A more in depth explanation of MoE is provided at the end of this article. The company’s flagship model, DeepSeek-R1, has demonstrated capabilities that rival OpenAI’s GPT-4, particularly in mathematical reasoning, coding, and structured tasks. What makes DeepSeek-R1 particularly remarkable, is its ability to achieve high performance while using significantly fewer computational resources. DeepSeek states that its V3 model was pre-trained using just 2,048 Nvidia H800 Graphics Processing Units (GPUs) over a span of two months, with each GPU operating at an approximate cost of $2 per hour. The total training cost amounted to $5.5 million, utilising 2.8 million GPU hours — significantly lower than the costs incurred by competing models.
A more in-depth explanation of Nvidia’s GPUs is provided at the end of this article. This efficiency has raised eyebrows across the industry, with some experts suggesting that DeepSeek’s approach could revolutionise AI development by reducing reliance on expensive hardware. However, DeepSeek’s claim has been met with skepticism. Industry experts question the feasibility of achieving such advanced AI capabilities with comparatively limited resources. Notably, Elon Musk has expressed doubts about the authenticity of DeepSeek’s claims, suggesting that the company might be understating its hardware usage. Additionally, reports have emerged that U.S. authorities are investigating whether DeepSeek acquired restricted Nvidia chips through intermediaries in Singapore, further fuelling concerns about the transparency of the company’s operations, these claims are not confirmed. Until independent research verifies DeepSeek’s claims, the true extent of its AI efficiency remains uncertain.
The Political and Economic Implications of DeepSeek’s Rise
DeepSeek has been making headlines not only for its technological advancements but also for its economic and geopolitical implications. Its rise has had a noticeable impact on the global AI industry, affecting market movements and strategic planning for companies heavily invested in AI hardware. One of the biggest shifts has been the sudden uncertainty surrounding Nvidia and ASML — companies that have dominated the AI chip market. Until recently, the assumption was that Nvidia would continue supplying increasingly powerful AI chips each year and that ASML would expand its production of cutting-edge chip-making machines. However, DeepSeek’s ability to achieve high performance with significantly fewer GPUs has disrupted these expectations. Investors are now questioning whether companies need to rely as heavily on Nvidia’s expensive hardware, which has led to a dip in the company’s stock prices. Moreover, if AI models such as DeepSeek-R1 require fewer high-end chips, it may lead to lower costs for businesses and startups looking to integrate AI into their operations.
In addition, the AI race between China and the United States has long been a focal point of international competition, particularly regarding high-end semiconductor manufacturing. If DeepSeek’s approach proves successful, it could reduce China’s reliance on high-end Western chips, thereby weakening the impact of U.S. export restrictions on Chinese technology firms. This shift also has major ramifications for AI research. Historically, Chinese researchers traveled abroad to study AI, with many working in the United States and Europe before returning home. However, computer scientists such as Maarten de Rijke have pointed out that this dynamic has changed. Today, Chinese researchers are responsible for 70–80% of publications in certain AI subfields, and Western countries increasingly depend on their expertise. The idea that China lags behind in AI research is becoming outdated, and as DeepSeek gains traction, it may accelerate the trend of China leading in AI development rather than following Western innovations.
Furthermore, in January, Italy’s privacy watchdog took action against DeepSeek, blocking access to its chatbot over concerns related to data security and compliance with European regulations. This move has sparked debates over whether AI models developed in China will face additional scrutiny in Western countries, especially given the growing concerns about data privacy and information control. Ironically, DeepSeek’s success stems from the very constraints meant to limit it. Restricted access to advanced chips forced the company to innovate, leading to its resource-efficient MoE architecture. Similar to Darwin’s theory of evolution, where species adapt to harsh environments, DeepSeek thrived by focusing on efficiency over brute computational power. These limitations, intended to hinder, instead spurred innovation, showing how constraints can drive progress and become an unexpected advantage.
Lastly, there are also concerns about the regulatory environment surrounding AI in China. Censorship remains a critical issue, and there are open questions about how DeepSeek’s models will handle politically sensitive topics. Many observers recall past instances where AI tools trained in China were restricted from discussing issues related to human rights and democracy. These concerns raise ethical considerations about AI development and the role of bias in large language models.
Thus, with DeepSeek’s rapid rise, many investors and industry leaders are now looking at how to position themselves in the AI sector. While OpenAI, DeepMind, and Anthropic remain dominant forces in the West, DeepSeek’s ability to achieve strong performance with lower computational costs could attract more investment in China’s AI ecosystem. Alibaba has already entered the competition by launching its Qwen 2.5 model, which reportedly surpasses DeepSeek’s V3 version, further intensifying competition within China. For investors, understanding the shift from compute-driven AI to algorithm-driven AI will be key in navigating the industry’s future. Historically, AI models have relied on brute-force computing power to improve performance, but DeepSeek’s success suggests that smarter architectures may be just as important as raw processing power. This could change how AI companies allocate resources and how investors evaluate which companies have the most promising long-term potential. In conclusion, DeepSeek represents both an exciting advancement and a challenge to the existing AI hierarchy. While its efficiency and technical breakthroughs have captured global attention, questions remain about its accuracy, reliability, and geopolitical impact.
Mixture of Experts (MoE) architecture explained
Figure 1
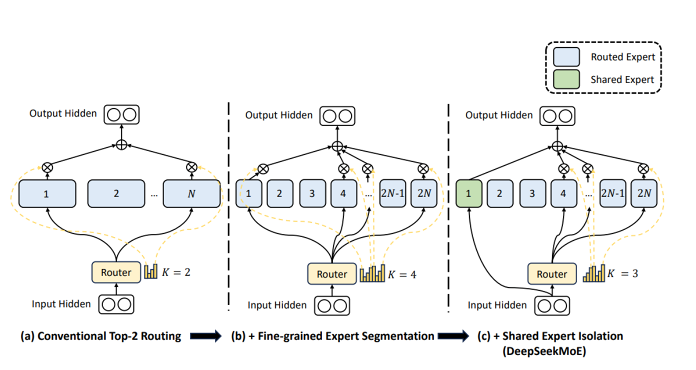
Figure 1 illustrates the architecture of DeepSeek’s MoE model, a design aimed at efficiently using specialised components within the AI system. In this figure, experts are specialised sub-models trained to perform specific tasks, such as solving mathematical problems, analysing emotions, or generating text. A router acts as the decision-maker, determining which experts are most suited to handle a particular input. The router uses predefined criteria to route the input to a subset of experts, ensuring that only the most relevant ones contribute to the output, thus optimising computational resources.
The figure progresses through three stages of complexity. In (a), the “Conventional Top-2 Routing” strategy is depicted, where the router selects two experts out of the available pool to handle the task. This approach is straightforward but limits flexibility. In (b), “Fine-Grained Expert Segmentation” is introduced, expanding the pool of experts and allowing the router to activate more experts for greater precision in handling diverse tasks. Finally, in (c), the “Shared Expert Isolation” strategy of the DeepSeekMoE architecture integrates shared experts—components that contribute to multiple tasks—alongside task-specific experts. This approach balances efficiency and performance by combining generalist and specialist capabilities.
DeepSeek employs this advanced MoE architecture, leveraging shared and task-specific experts to reduce computational demands without compromising performance. In contrast, models such as OpenAI’s ChatGPT and Google Gemini use dense architectures, where all model parameters are activated for every task. While dense models are versatile, they require significantly more computational power. DeepSeek’s approach, by selectively activating only relevant experts, represents a more resource-efficient alternative, setting it apart from traditional AI systems.
Nvidia GPUs explained
Nvidia is a fabless semiconductor company, meaning it designs its chips but outsources manufacturing to companies such as TSMC (Taiwan Semiconductor Manufacturing Company). This allows Nvidia to focus on research, innovation, and software development while relying on third-party manufacturers for production.
Nvidia GPUs (Graphics Processing Units) are powerful chips originally designed for rendering graphics in video games. Over time, they have become essential for high-performance computing, artificial intelligence (AI), and deep learning. Unlike traditional CPUs (Central Processing Units), which handle tasks sequentially, GPUs process thousands of tasks simultaneously, making them ideal for AI training, scientific research, and large-scale data analysis. Modern AI models, such as ChatGPT, DeepSeek, and Gemini, require massive amounts of computational power to process vast amounts of data. Training these models involves performing billions of mathematical calculations, making GPUs the preferred hardware due to their ability to handle parallel processing efficiently. Nvidia dominates the AI chip market, producing some of the most powerful GPUs, including the A100, H100, and H800, which are widely used by AI companies.
Nvidia A100 was one of the first GPUs optimised for large-scale AI and machine learning, it was used in training ChatGPT-3 and GPT-4, among other AI models. The successor is the H100, offering faster processing speeds and better energy efficiency and is used by OpenAI, Google DeepMind, and other AI labs to train large language models. It also supports Transformer Engine, which improves AI model training speeds. Due to U.S. export restrictions, Nvidia created the H800, which has lower performance limits than the H100 but still provides powerful AI capabilities.
Author: Lucy van Eck
Editor: Kim Steen
Sources:
https://foreignpolicy.com/2025/02/05/deep-seek-china-us-artificial-intelligence-ai-arms-race/
https://thediplomat.com/2025/02/is-chinas-deepseek-using-smuggled-ai-chips-from-singapore/
https://www.investopedia.com/deepseek-ai-investing-8782152
https://edition.cnn.com/2025/01/29/china/deepseek-ai-china-censorship-moderation-intl-hnk/index.html
https://www.investopedia.com/deepseek-ai-investing-8782152
https://www.nvidia.com/en-us/data-center/a100/
https://www.techpowerup.com/gpu-specs/h800-sxm5.c3975